Webパフォーマンスの振り返り 2022年
揺らぐ通信インフラへの信頼
今年、最も衝撃的だったのは、相次ぐ通信インフラの障害だったのではないでしょうか?
絶大なる信頼を寄せていた通信インフラが障害で接続障害に陥る、というのは、日本人としては驚きの事態でした。
私たちの心の中には、「品質の日本」という自負みたいなものがあります。
サイレント障害
ネットワーク上で発生する、エラーとして検知されない障害を「サイレント障害」と云います。
その多くは、自社のインフラだけを見ていて、その稼働状態だけでシステム稼働の正常・異常を判断することが原因です。
携帯網については、有線回線とは異なる複雑な仕組みと、電波を使っているという事もあって、サイレント障害の検出のソリューションは、End-to-Endの通信監視・計測による手法が以前より世界で普及していました。
それを販売していたのは、ドイツにあるSIGOSという会社です。
世界で一番はじめにWebパフォーマンス計測サービスを始めたKeynote Systemsが、2006年4月に買収して、Keynote SIGOSとして世界のモバイルオペレータに販売して、全世界のマーケットシェアの90%以上を持っていました。
計測手法としては、携帯基地局のところに計測機器を設置して、そこにバーチャルSIM(当時は、まだeSIMは無かった)もしくは実際のSIMを挿して、携帯端末と同じように携帯網に接続して通信状況を監視するというものです。
バーチャルSIMとは、SIMに記載されている情報を転送して利用する仕組みです。
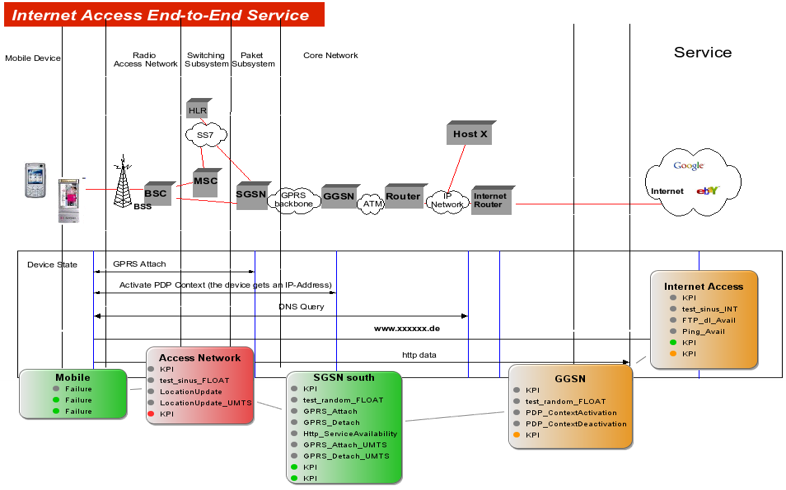
SIGOSのテストは、携帯サービスの殆ど全てをカバーできるものでした。

残念なことに、日本においては、実証実験的な導入であったり、導入しても一部にしか適用しない、ということで携帯網全体をテストするところまでは普及しませんでした。
あと、日本の場合は、常時接続テストより、カバーエリアのテストの方に注力していた、という事情もありました。
そのことが、最終的には、障害検知の遅延であったり原因特定まで時間が掛かる事態を引き起こしていると考えます。
SIGOSは、Keynote SystemsのCEOであるUmang Guputa氏が、投資会社のThomaBravoに売却後に再び独立会社となり、2020年にMobileumに買収されました。
今年の4月には、日本法人ができているので、今後に期待しています。
※Umang Guputa氏は今年亡くなりました。ご冥福をお祈りします。あなたに認めて頂いて、今の私がいます。
IP層まで保証できればいいのか?
本来、ネットワークを提供しているインフラ側としては、IP層まで保証できていればいいわけです。
その上の層は、上の層を利用したサービス事業者の問題ですし、憲法21条2項にある通信の秘密もあるので、基本ノータッチでした。
ところが、昨今は、そういう責任範囲の分担(=分断)も上手くいかなくなりつつあります。
通信というのは、利用者からすると、Webやゲームや動画などのIP層より上の層のサービスによって可視化されるものです。
IP層までが接続保証できていれば問題ない、というのは消費者心理としては理解し辛いです。
そこで、世界では、徐々に上のレイヤーについても責任はないけど計測・監視しようという流れになってきています。
例えば、アメリカのVerizonは、全米1万箇所に、Catchpointの計測ノードを設置して、Verizonの回線上で主要なWebサイトやサービスなどの計測・監視を行っています。
航空機内でのインフライトWiFiによるインターネット接続サービスの機器を販売しているHoneywellも、Catchpointの計測機器を設置して通信状況の計測・監視を行っています。
下のレイヤーの計測・監視を始めた上位レイヤー層のサービス事業者
インフラ事業者が、徐々に上のレイヤーのサービス計測・監視を始めたのと呼応するように、Webサービスやコンテンツ事業者側もサービス計測・監視対象を下のレイヤーへと下ろし始めました。
日本でも、弊社のお客様を中心としてBGP監視や、Tracerouteによる経路・レイテンシ計測・監視、DNS計測・監視などをされています。
もちろん、Catchpointを利用している主要なアメリカやヨーロッパの企業、MicrosoftやGoogle、Oracle、AWSなどのIT企業や、Webサービス、CDN事業者、メディア、ECサイトなども始めています。
この背景にあるのは、自社が主に利用しているHTTPSの処理だけを計測・監視しているのでは不十分であり、結局のところ、インターネットというのはインターネットスタック(インターネット・プロトコル・スイートとも云います)を監視しなくては、サービスレベルの保証と維持ができないという認識が広がっているからなのです。
例えば、画像ファイルのダウンロードがWaterfall Chartで遅延している場合に、その原因をきちんと突き止めようとすると、以下の確認が必要です。
- HTTPSでの画像ファイルのダウンロードが遅い
もしも、インターネットスタック全てをカバーした計測・監視をしていないと、「画像が重いからだろうから、軽量化しよう」という誤った結論にたどり着いてしまうわけです。
また、このインターネットスタック全てをカバーした計測・監視は、各地方都市、各ネットワークで行う必要があります。
もちろん、因果関係を明確にするために、他の変数(マシンスペック、OS、ブラウザのバージョンの違い、他にマシン上で動いているプロセスなど)を止める処理も必要です。
更に、エラーも確実にキャッチして発見する必要があります。
(※RUM: Real User Monitoringでは、エラーが発生したら、その通知を送ることが難しいため。
例えば、DNSがエラーになったら、どうやって、HTMLを読み込み、データを送るJavaScriptを起動できるのでしょうか?)
だからこそ、実験計画法に準拠したSynthetic Monitoringで、全国各地の携帯回線や光回線を使って計測する必要があるわけです。
レイテンシへの注目
今年は、レイテンシに関する話題が多かったです。
P99Confでも、レイテンシに関する講演が多かったです。
多くの企業で、インターネットスタック全てをカバーした計測・監視が行われるようになって、レイテンシの重要性が改めて認知されるようになりました。
特にネットワークのレイテンシは、パフォーマンスチューニングにおいて、超えられない壁です。
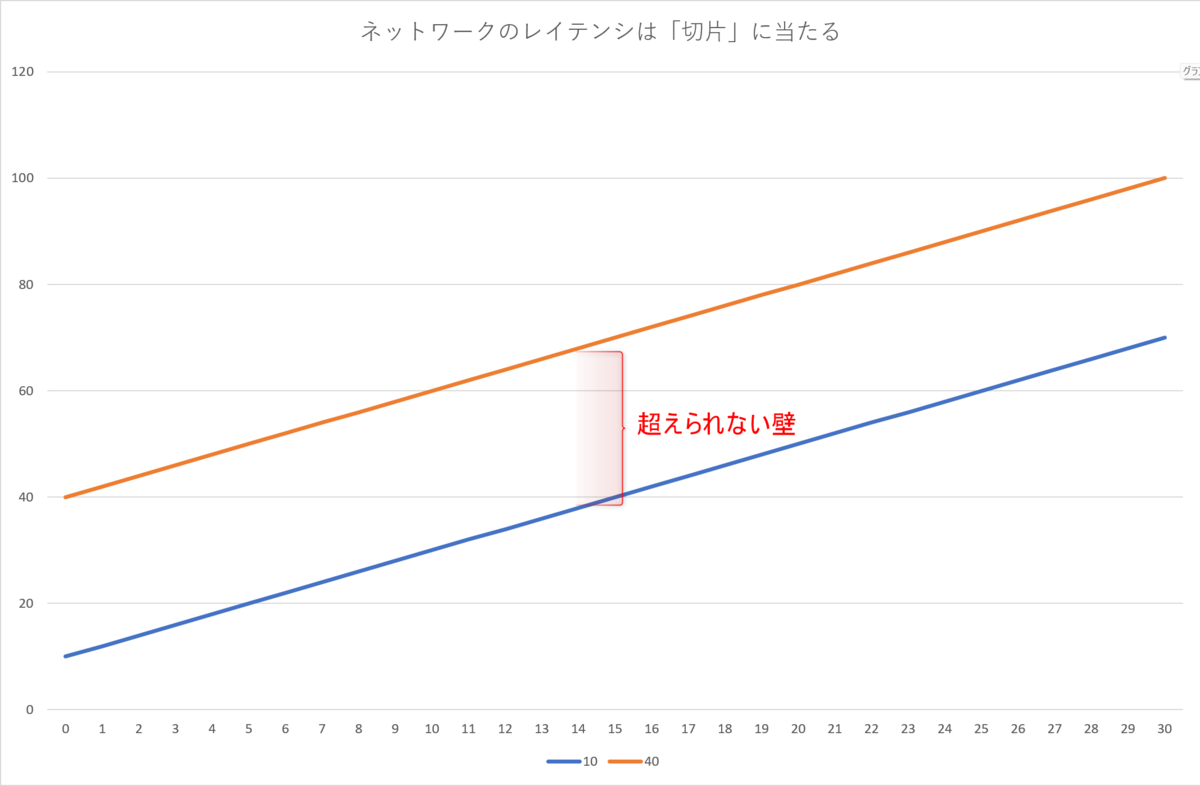
中学の数学で、1次関数を学びます。
1次関数でxが0の時のyの値、つまりグラフのスタート地点を「切片」と呼びます。
ネットワークのレイテンシは、1次関数の切片と同じです。
ネットワークのレイテンシは、小さいパケットを往復させての時間ですから、実際のネットワーク処理時間は、それよりも必ず大きくなるのです。
光回線のレイテンシは2~10ms程度です。
レイテンシが10msなら、どんな処理も10msより高速になることはありません。
携帯回線のレイテンシは25~60ms程度です。
レイテンシが40msなら、どんな処理も40msより高速になることはありません。
- DNS = レイテンシの時間 + DNSの処理時間
- TCP 3way handshakes = レイテンシの時間 + TCPの処理時間
- SSL = レイテンシの時間 + SSLの処理時間
- ファイルのダウンロード = レイテンシの時間 + ファイルのダウンロード処理時間
レイテンシは、全ての処理で加算され、積み重なっていきます。
下記の散布図は、ドコモの5G回線のレイテンシ、ホップ数、パケットロスの散布図と、同時間のSpelldataのコーポレートサイトのHTMLレスポンスタイム、Render Start、Document Completeの散布図です。
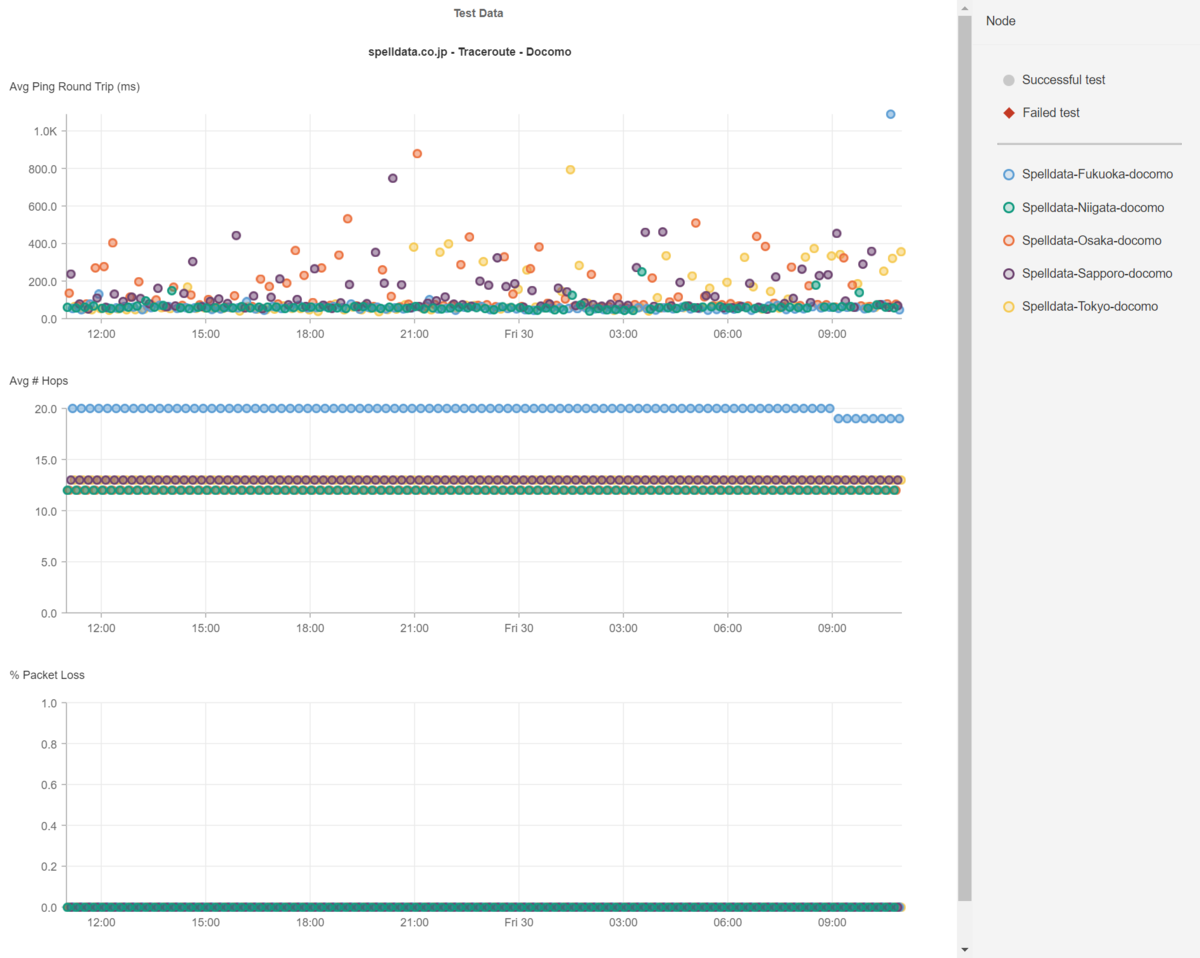
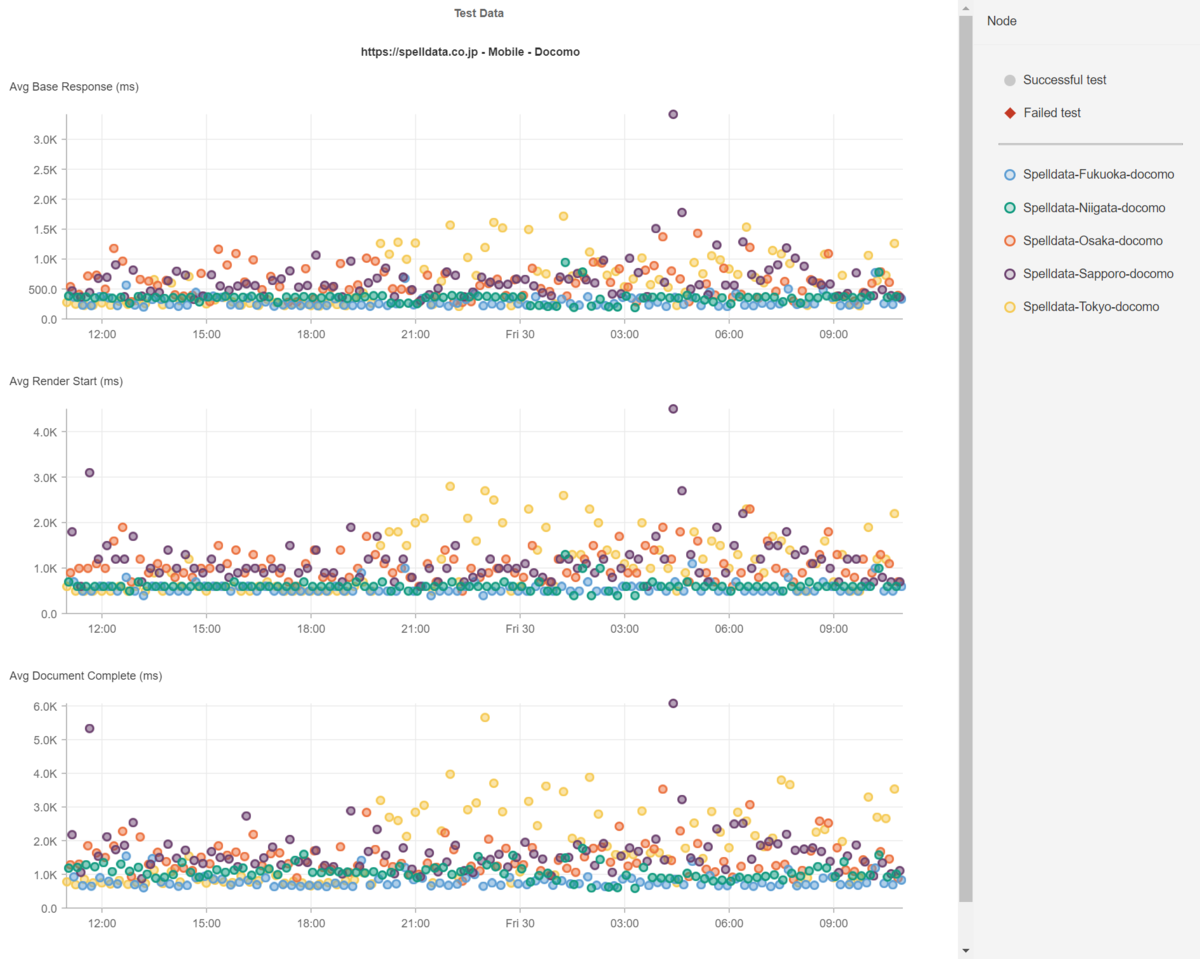
札幌、東京、大阪でレイテンシが遅延しています。
その分、WebページのHTMLレスポンスタイム、Render Start、Document Completeも遅延しています。
このように、長期間に亘ってレイテンシが遅延している場合には、レイテンシの影響であると分かりやすいです。
問題は、短期間で変化するレイテンシです。
光回線のレイテンシ
「光回線は品質が良い、だからレイテンシは常に一定」と、決めてかかっていませんか?
もちろん、品質管理がしっかりしている事業者ならある程度はそうですが、全てが品質が良いわけではないです。
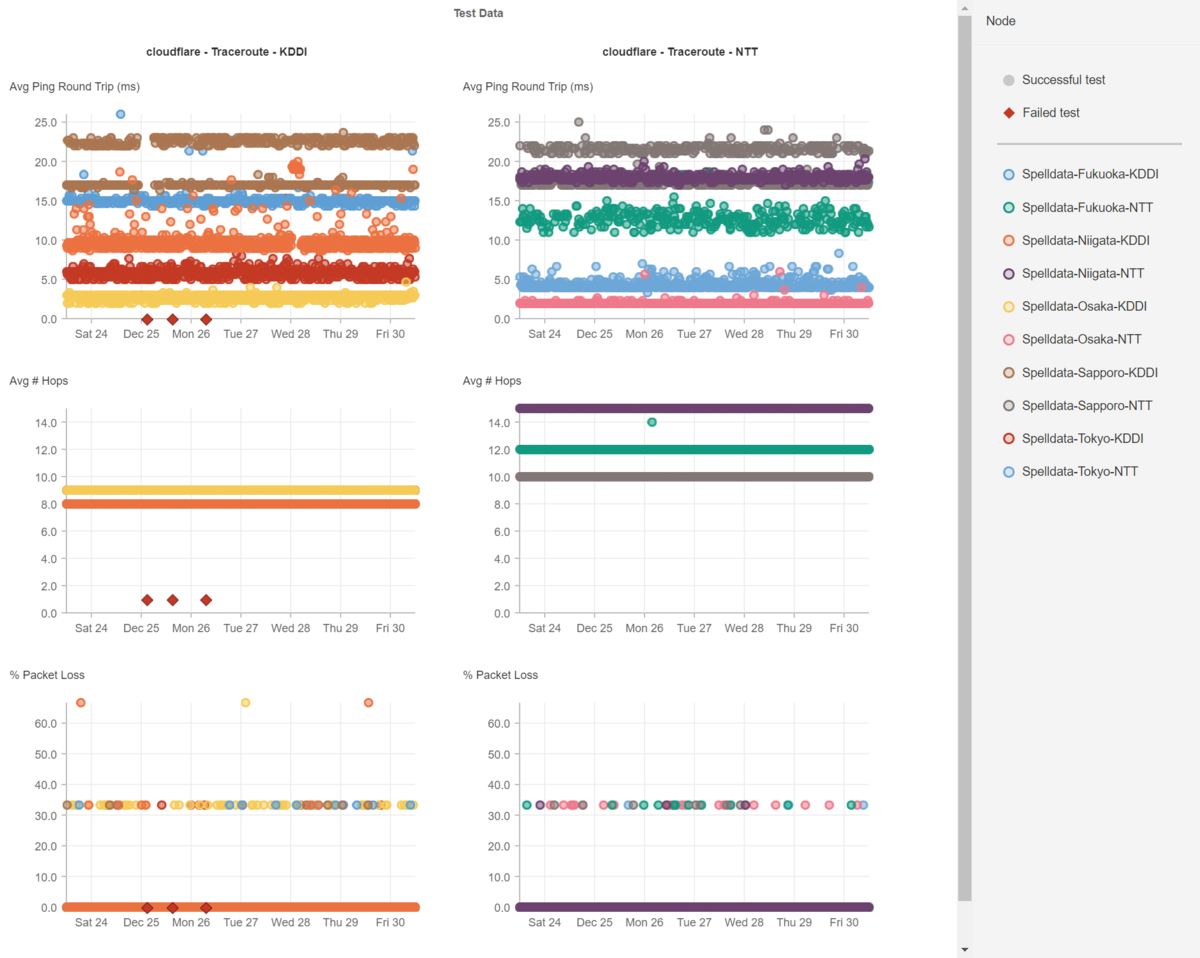
以下にNTTとKDDIの光回線のレイテンシの一週間分の散布図を掲載します。
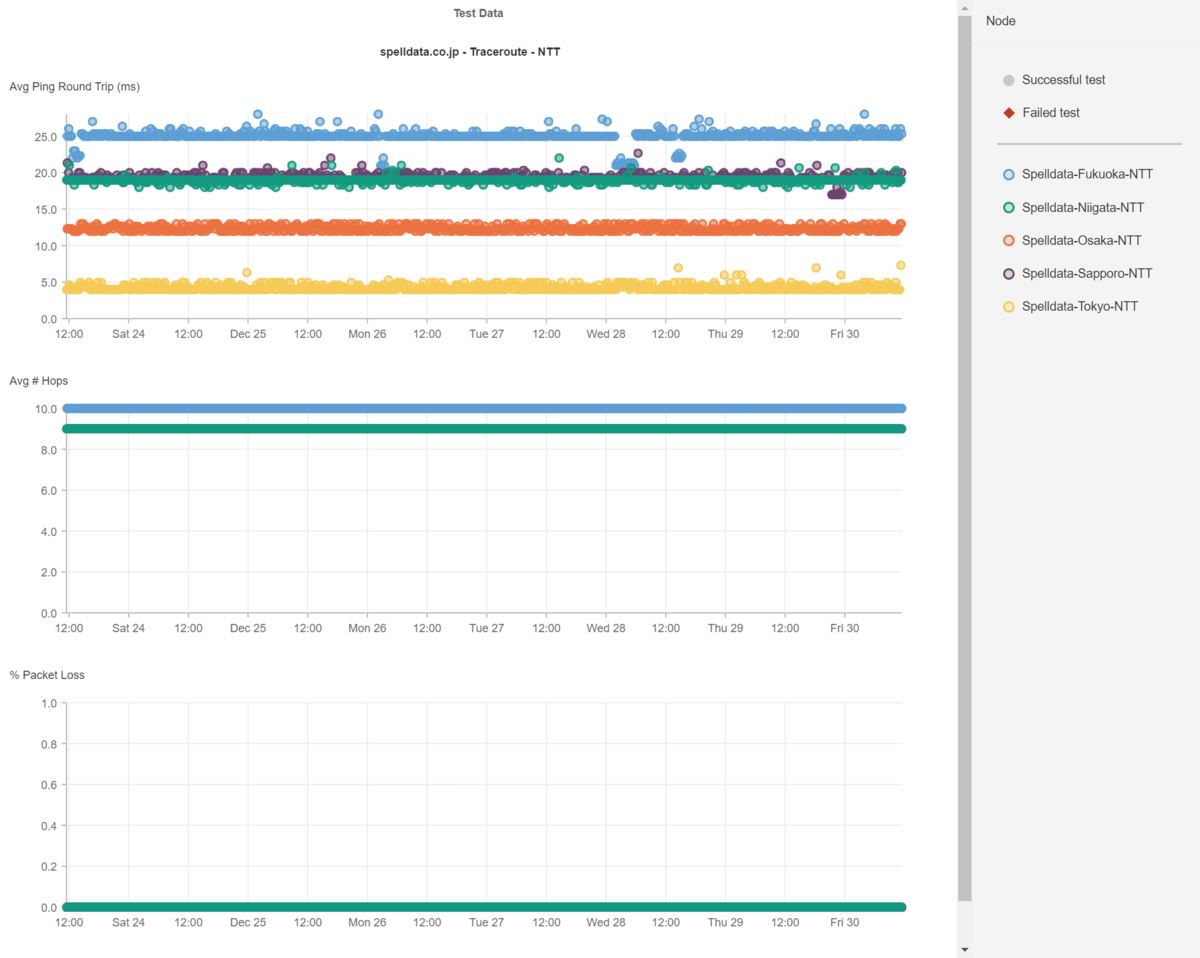
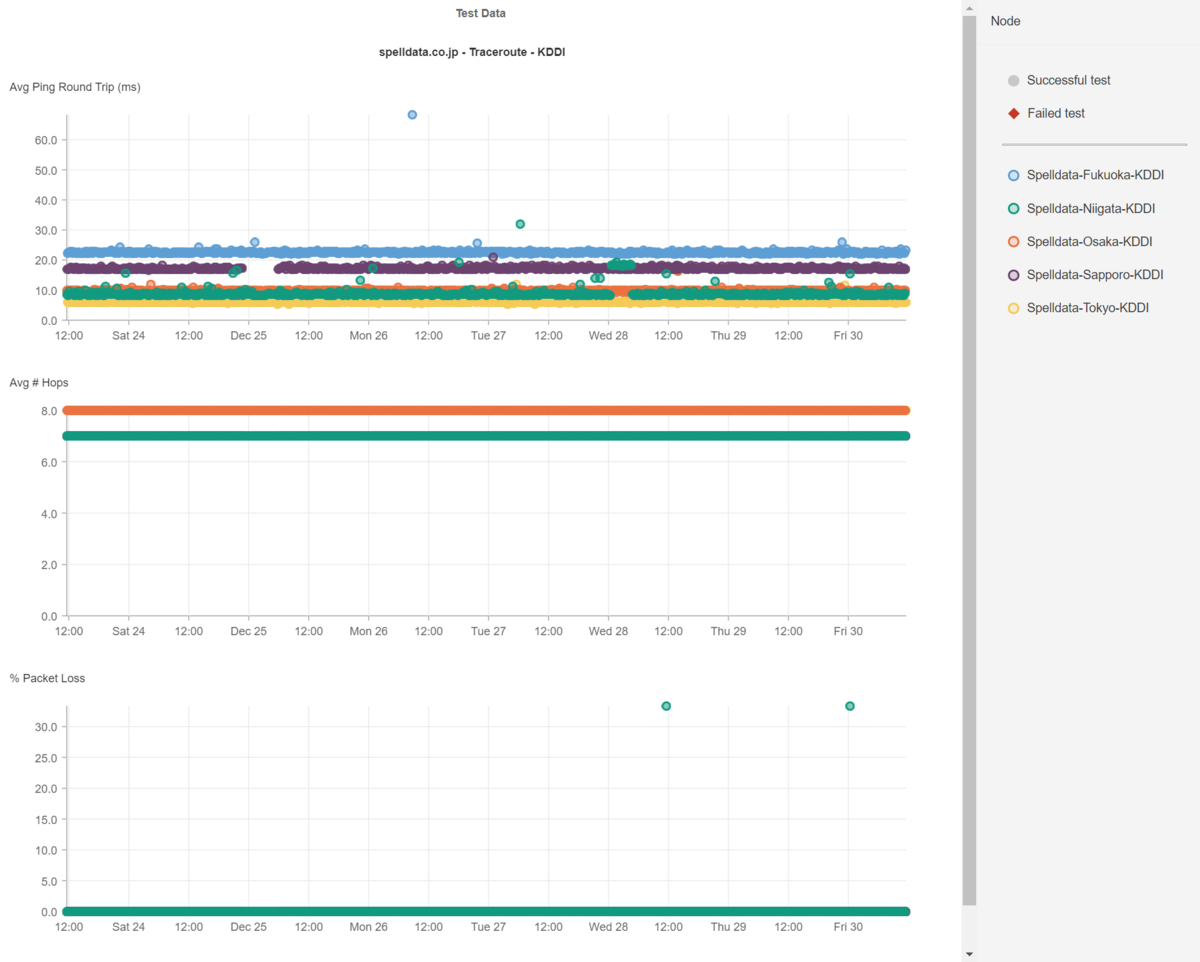
世の中の全ての事象はバラツキを生じます。
当然ながら、光回線のレイテンシもバラツキを生じます。
ですから、各都市でのレイテンシも特定のミリ秒で並ぶのではなく幅を持っていて、且つ、時折遅延したり、高速になったりしています。
では、皆さんが高速化した!と喜んで見ている数値は、どの位レイテンシの影響を受けているでしょうか?
その高速化できた数値は、たまたま、回線のレイテンシが速かったからだとは言えませんか?
ここで、24時間365日、ネットワークのレイテンシを計測・監視する意味があるのです。
このようなデータを見せると、「うちは、ネットワークの負荷が上がらないようにICMPのパケットは落としてるんだ」と仰る事業者さんもいます。
ネットワーク機器には、CPUの負荷に応じて、ICMPを落とす機能を実装しているものがあります。
しかし、ICMPではなく、TCPやUDPを使ったtracerouteでも、同じ結果になります。
いずれにせよ、CPUの負荷増大ということは、それだけのパケットが流れているというわけですから、設備投資が不足していることを意味します。
CDNのレイテンシ
WebサイトがCDNを利用している場合は、当然ながら、CDNのレイテンシに大きく影響を受けます。
しかし、殆どのCDNを利用している企業は、CDNのレイテンシの計測・監視はしていないので、レイテンシがどうなっているかを知りません。
もちろん、CDNもレイテンシが遅延すれば、Webサイトも遅延します。
以下に、Akamai、Cloudflare、CloudFront、Fastlyのレイテンシを掲載します。
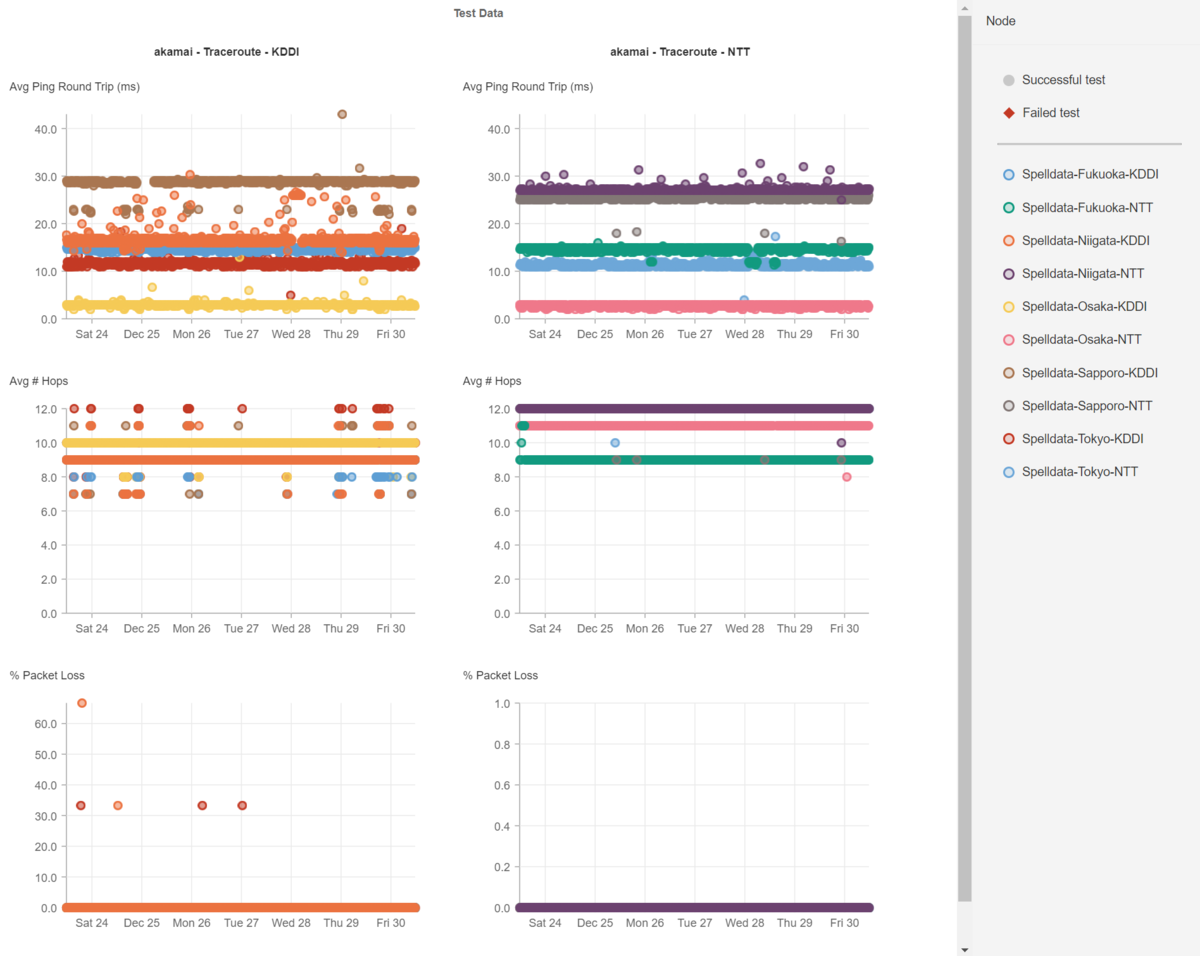
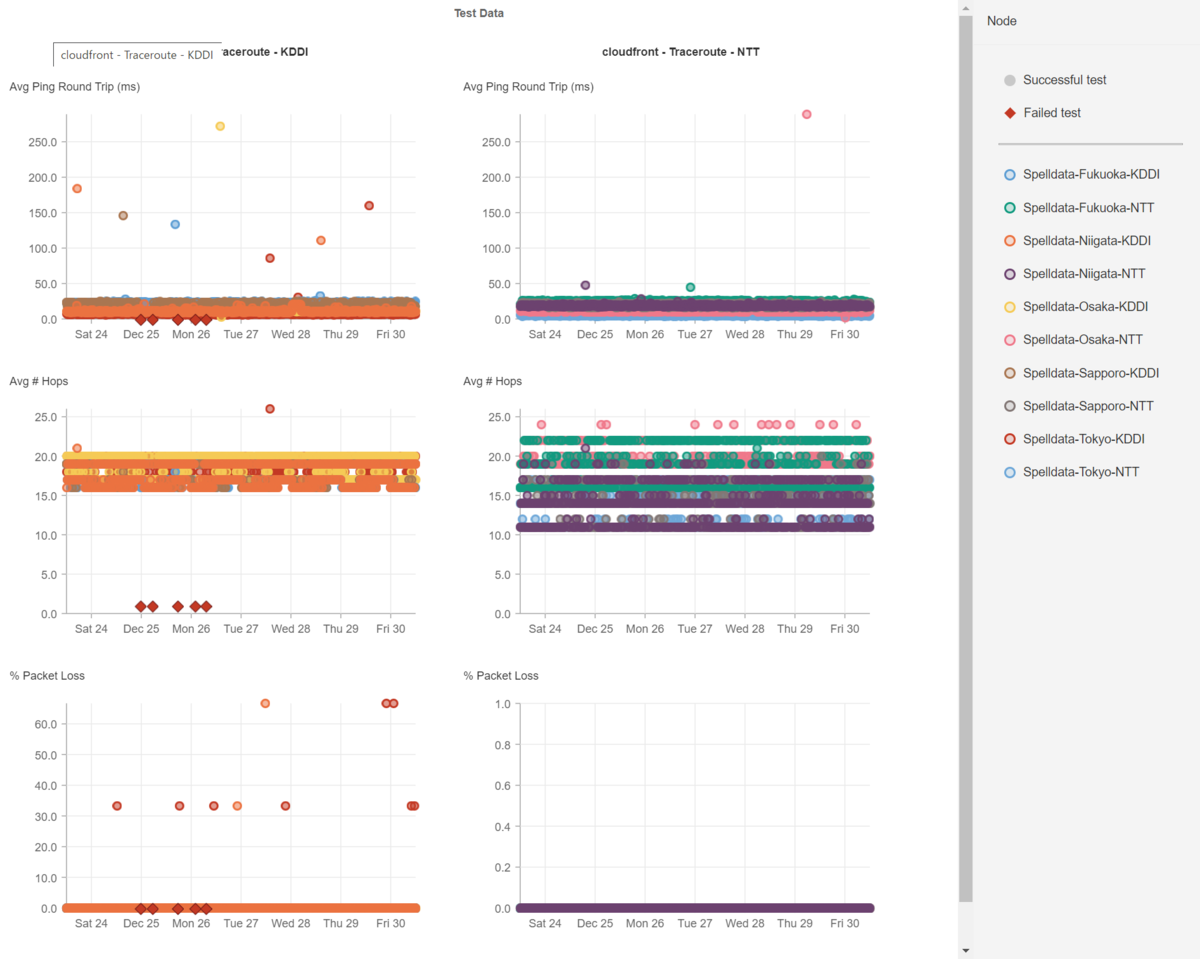
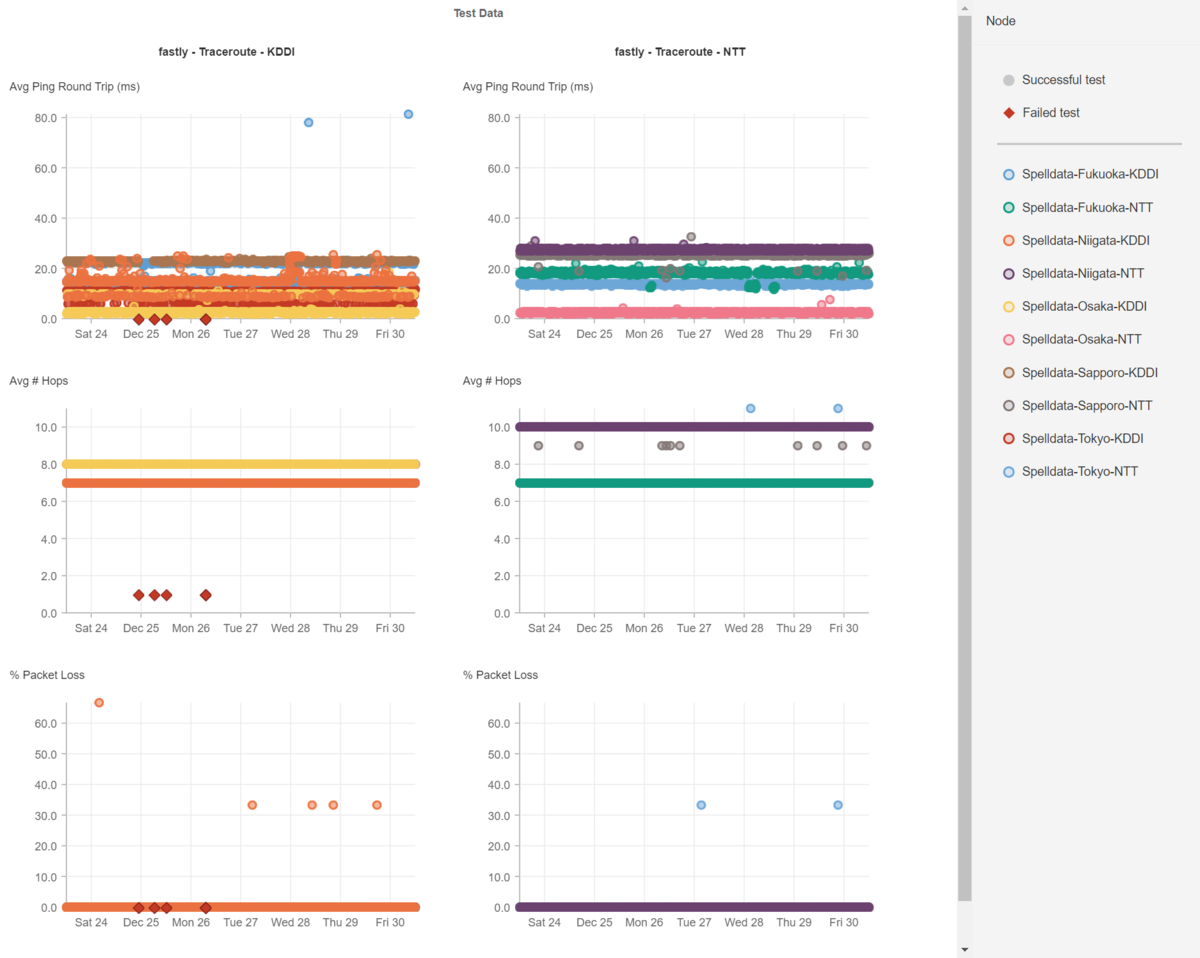
このように、CDNもバラツキが生じるため、CDNを利用したシステムのパフォーマンスの分析も、速くなった・遅くなったという結果を見る前にCDNのレイテンシを確認する必要があります。
NURO光の炎上に見る帯域幅神話
今年の9月にNURO光の遅延についての炎上がありました。
NURO光、集団訴訟を検討中です。
— ゴールデンボル男 (@Goldenballmen) September 21, 2022
集団訴訟を検討している理由として↓
①広告で「高速回線」を謳っているのに夜間帯の明らかな速度低下(景品表示法違反)
② 総務省が定めているパケロス率「0.1%」を超える平均10%近い数字が出ている(電気通信事業法違反)
続きます
このツイートに対して、「遅くないよ」とスループットの計測の結果を返した人たちがいました。
長らく、スループットで回線品質を測るという習慣のためでしょう。
よく「ブルーレイディスク1枚分の映画のダウンロードが○○秒で終わる」などと書かれますが、そんな使い方をしている人は殆ど居ないでしょう。
今のネットの利用は、殆どがストリーミング型、つまりゲームや動画など、ずっと通信が発生しているが、それほど高スループットが必要なわけではなく、レスポンスタイムの速さが求められるサービスです。
そういうサービスについては、スループットより、レイテンシやパケットロスが0であることの方が重要です。
大容量のダウンロードは、例えて言うと「押出し成形」のようなものです。
スループットは、たとえパケットロスが発生していても、ファイル容量が大きいほどに、TCPのパケットの再送要求の恩恵もあるため、有利な数値が出ます。
そして、ブロードバンドテストの殆どは、大きくても25MB程度のファイルをダウンロードして計算された推測値であることに注意して下さい。
1GBのファイルをダウンロードしているわけではないのです。
例えば、Netflixが提供しているfast.comの計測方法については、以下のブログで解説しています。
25MBのファイルであれば、数秒でダウンロードが終わります。
(現在、トップページが25MBあるサイトの高速化を行なっていますが、それでも高速化で1秒で表示完了です。)
その間にパケットロスが発生しなければ、当然ながら、スループットの数値は良くなります。
たとえパケットロスが発生したとしても、瞬停みたいなものであれば、TCPの再送要求で埋め合わせができます。
ネットワークのパケットロスは、連続して発生しているわけではなく、離散して発生しています。
下記は、アルテリア・ネットワークスの光回線でのパケットロスの例です。
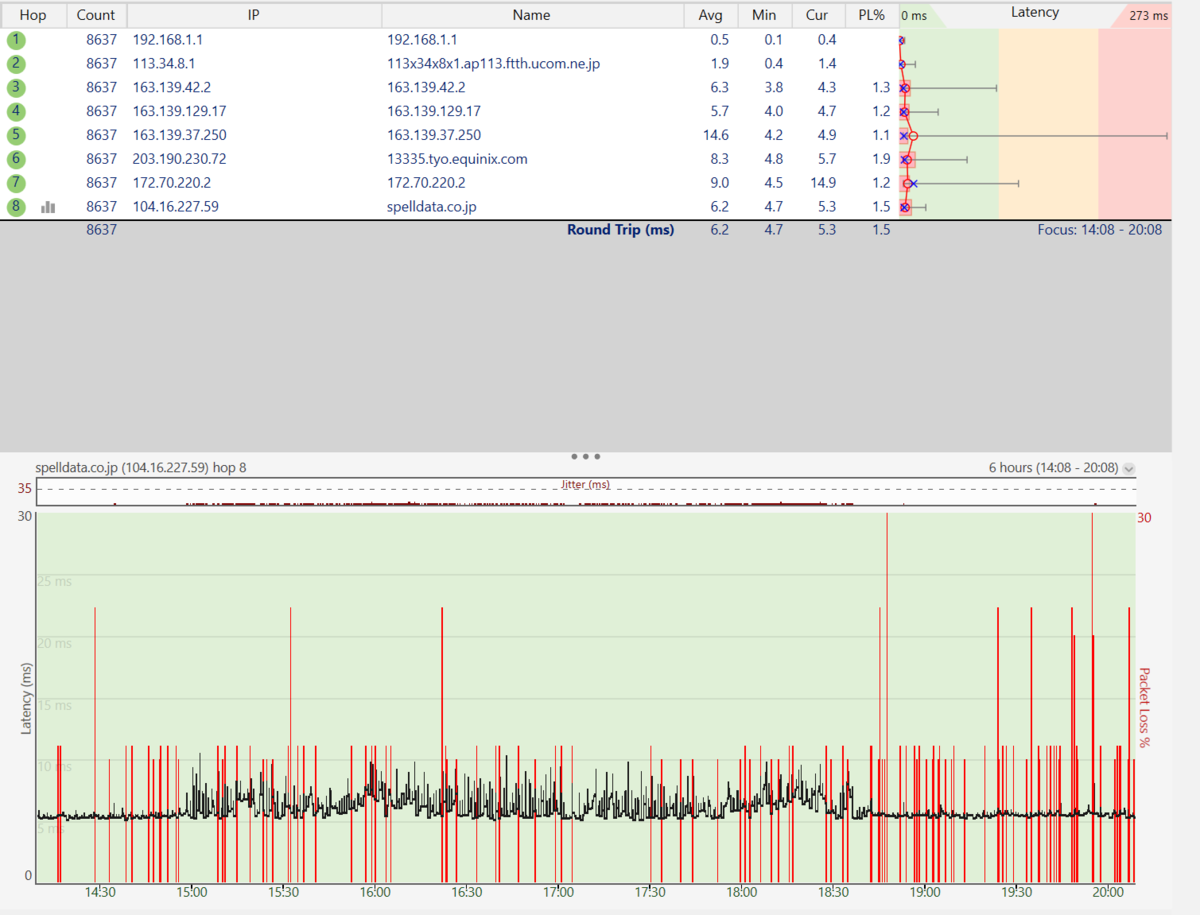
この件について、アルテリア・ネットワークスのサポートが1分ぐらいtracerouteを行って問題無いという結論を出してきたので、長時間の計測でエビデンスを出しました。
しかし、結局は「契約書で保証しているわけではない」と開き直ってしまいました。
こういうことは、回線業者だけではなく、データセンター、CDN業者でもあります。
デジタルサプライチェーンをどうマネジメントしていくか
現在のWebサイトやモバイルアプリなどは、製造業のサプライチェーンにそっくりです。
殆どのWebサイトは、自社のサーバだけで成り立っているというものは少ないです。
インフラにはクラウドサービスを使い、回線業者の回線を利用し配信し、Webページには様々なサードパーティーコンテンツが埋め込まれています。
例えば、Yahoo! JAPANのトップページは、以下のようなデジタルサプライチェーンから成り立っています。
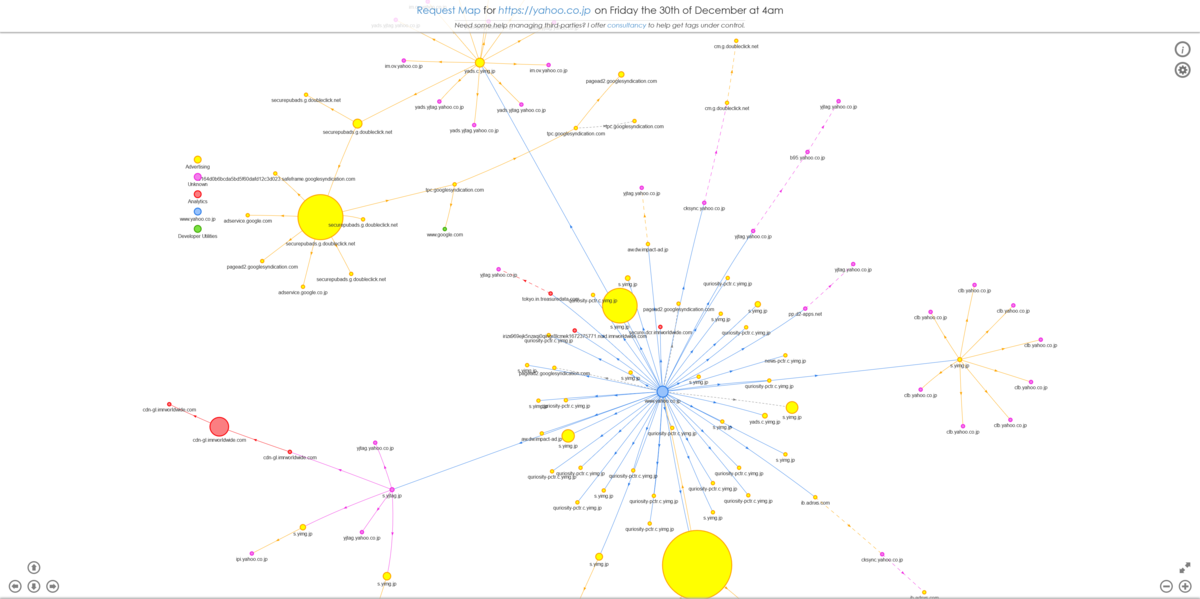
これは、Catchpointが提供しているWebPageTestでテストすると、メニューの「Request Map」から生成できます。
もしも、このサプライチェーンのどれか1つでも遅延すれば?
それが表示と依存関係を持っていれば、当然ながら遅延します。
IPM (Internet Performance Monitoring)の重要性
オブザーバビリティの掛け声と共に、APM(Application Performance Management)を導入した企業は多いですが、しかしそれだけではシステムの性能と可用性を担保はできません。
インターネットスタック(インターネットプロトコルスイートとも云います)を計測・監視するIPM (Internet Performance Monitoring)が必要なのです。
もちろん、多くのSREを始めとする技術者にとっては、計測・監視のコストをどのように経営陣に理解してもらうかは悩みでしょう。
しかし、技術者の皆さん、経営陣は儲かる投資なら歓迎なのです。
私の会社Spelldataでは、表示完了を全国で98パーセンタイルで1秒以内にするところまで高速化します。
(実際のところ、バラツキを考えて、表示完了500ms以下までチューニングするんですが)
高速化で、押し並べて、どのお客様も年30%前後の増益を毎年達成しています。
1.3 * 1.3 = 1.69ですから、2年で1.7倍の売り上げになっています。
3年なら、1.3 * 1.3 * 1.3 = 2.197倍です。
Webサイトの高速化が売り上げにダイレクトに影響を与える件について、ビジネスの現場では、まだ腑に落ちていない方が多いみたいです。
しかし、いまだにそんなことを言ってる企業は、先が無いと思えます。
今では、アメリカの大学生が学ぶノーベル経済学賞を受賞した「情報経済学」を学んでいれば、なぜ、情報伝達速度が影響を及ぼすかが理解できるのですが、経営陣がそういうのも知らないというのは、経営者として終わってるとも言えます。
品質は、ビジネスの基本であり、ビジネスの力です。
ビジネスモデルがしっかりと確立していれば、の話ですが。
ですから、全ての企業にWebパフォーマンスにお金を掛けたらいいとはオススメはしません。
ビジネスモデルにボトルネックがある場合は、どんなにWebサイトを高速化してより良い顧客体験を提供したとしてもコンバージョンに結びつきません。
この場合には、まずはビジネスモデルの最適化が優先です。
創業からある程度の年月が過ぎていて、数十億円~1000億円の売上がある?
ならば、ビジネスモデルは確立しているでしょう。
CatchpointのIPMを導入することで、確実に高速化のためのボトルネックを明らかにして高速化し、増益への貢献によって会社内での評価を勝ち得て下さい。
IPMや、Webパフォーマンスの高速化については、こちらで承ります。