「外形監視」という訳語の間違い
要約
Synthetic Monitoringに「外形監視」という訳語を当てている方がいるのですが、Syntheticの意味は「外形」ではありません。 Syntheticは「合成」という意味です。 ですから、日本語訳を付けるのであれば、「合成監視」です。
また、External Monitoringの訳語として、「外形監視」という訳語を当てて書いている人も見かけます。
正しくは、
- Synthetic Monitoring ... 合成監視
- External Monitoring ... 外部監視
です。
何故、Synthetic Monitoringは、「合成監視」なのでしょうか? その歴史と背景を解説します。
Synthetic Monitoringとは何か?
Synthetic Monitoringとは、計測システムから、対象システムに対して能動的にアクセスして、性能や可用性に関するデータを取得する仕組みです。
この手法を一番最初に始めたのは、Keynote Systemsという会社で、頻度論ベースの統計的品質管理の手法に則って、計測が行われます。
観察データではなく実験データ
Synthetic Monitoringは、観察データではなく、実験データを取得します。 実験データとは、実験デザインを行い、それに従い実験介入を行い、データを取得します。
フィッシャー三原則
実験介入を行って計測するという手法は、統計データを取る基礎です。
現在統計学の父である、R・A・フィッシャーが確立した「フィッシャー三原則」というものがあります。
- 反復
- 無作為化
- 局所管理下
反復
この世の全てのものは、「バラツキ」があります。 一意に値がぴったりと定まって、常にそうであるというものはありません。
2023年の今日では、計測・監視を導入する企業も増えたので、計測・監視データを見ている技術者は、そのことはよくお判りでしょう。
統計分析は、変化量を捉えて理解し(記述統計)、そこからモデルを作って将来の予測を立てる(推測統計)ために行います。 そこで、変化量を捉えて分析する際に、重要になるのが、微分・積分なのです。
計測して得られた観測値が、そのまま信頼できる値か?というと違いますよね。 例えば、今日の10時に計測・監視して得られた値が、未来永劫、変わらず、そのままなら、品質管理なんていらないです。 どうしてもバラツキを生じて変化していきます。
では、1時間ごとに計測・監視すればいいでしょうか? しかし、1時間ごとだと、その60分の間、値が変わらないと言えるでしょうか? 変化を捉えるため/変化していないのを捉えるために、どのくらいの間隔で、計測するのが妥当なのでしょう? 30分?15分なら?10分?5分?1分?
ここで統計学での頻度論の知識が必要になるわけです。
頻度論は、「標本の大きさが大きくなるほどに、真の値に確率的に近づいていく」という考え方です。 Webパフォーマンス計測・監視の場合は、真の分布に近づいていく、という表現の方が良いでしょう。
できれば、1日あたり100の標本の大きさは確保したいところです。 15分に1回計測すれば、96の標本の大きさになり、100に近いですよね。
データを2倍の精度にしたい場合は、必要な標本の大きさは2倍ではありません。 2乗になります。 (なぜ2乗なのかは、分散、標準偏差の計算を学ぶと分かります。) ですから、100の2乗=10,000の観測値が必要となります。
統計学は「ケチの学問」と言われるそうで、できるだけお金を掛けずに、ある程度確からしい知見を得ることが目的になります。 観測値を増やせば、それでいいかというと、そんなことはなく、観察者効果を考えなくてはいけません。 多すぎず、少なすぎず、適切な標本の大きさを確保することで、検出力(差があるということを検出する力)を確保するのです。
ここで、正規分布とか、標本分布のt分布とか、そういう知識が必要になってきます。 パフォーマンスにおいては、ポアソン分布や指数分布も重要な知識です。 これは、パフォーマンス分析・設計で重要なM/M/1待ち行列モデルでも使います。
無作為化
無作為化とは、ランダムに計測・監視を行うという事です。 「系統誤差を偶然誤差に転化する」ために行います。
たまに、「9:00、9:15、9:30、9:45と、きっかりに計測して欲しい」という方がいます。 無作為化では、「9:01、9:14、9:32、9:46」のように15分間隔で計測・監視します。
局所管理下
因果関係を明確にするために、影響のある変数を明確にするために、他の変数を「止める」(固定化)します。
例えば、以下のような変数を止めます。
- マシンスペック
- OSのバージョン
- ブラウザのバージョン
- 回線の帯域幅
計測環境はできるだけ、性能が良いもので揃えます。 性能が良い環境で遅ければ、確実に遅いと言えるからです。 帯域幅が狭い回線だったり、スペックの低いマシンで計測すると、遅い結果が出た場合に、「それは回線の帯域幅のせい」「それはマシンが遅いからでは?」と言われてしまいます。
1Gbpsの品質が良い光回線を使って、スペックが高いマシンで計測して、それでもWebページが遅ければ、確実に遅いわけです。 言い逃れはできません。
Webパフォーマンスは、非機能要求に属する性能や可用性に関する事項であり、品質管理の分野です。 品質管理の目的は、設計品質(目標とする品質、Webパフォーマンスなら、表示開始や表示完了が全体の何パーセンタイルまで実現できるか)に対して、実際どれだけ達成しているのか(適合品質)を確認し、品質不適合品を世に出さないために行います。 つまり、速いことを証明するのではなく、遅いものがないことを証明するために行うのです。 遅いものがないことを証明するには、計測し続けるしかないのです。
Synthetic Monitoringは、Synthetic Dataを取得するから
では、Synthetic Monitoring、なぜSyntheticという言葉がついているのでしょうか? それは、データ分析におけるSynthetic Dataとか、Synthetic Datasetという言葉に由来しています。
WikipeidaのSynthetic Dataでは、以下のように説明が書かれています。
Synthetic data is "any production data applicable to a given situation that are not obtained by direct measurement" according to the McGraw-Hill Dictionary of Scientific and Technical Terms; where Craig S. Mullins, an expert in data management, defines production data as "information that is persistently stored and used by professionals to conduct business processes."
マグローヒルの科学技術用語辞典によれば、合成データは「直接測定によって得られていない所定の状況に適用できる生成データ」である。データ管理の専門家であるクレイグ S. ムリンズは、生成データを「ビジネスプロセスを実行するために専門家によって持続的に保存され使用される情報」と定義している。
データサイエンティストのTirthajyoti Sarkar氏の「Synthetic data generation — a must-have skill for new data scientists」という記事での説明は、もう少し分かりやすく書いています。
As the name suggests, quite obviously, a synthetic dataset is a repository of data that is generated programmatically. So, it is not collected by any real-life survey or experiment. その名前が示すように、合成データセットはプログラムによって生成されるデータのリポジトリーです。したがって、実際の調査や実験では収集されません。
Webパフォーマンスの計測・監視における「データ」
Webパフォーマンスの計測・監視における本来の「データ」は、実際に、ユーザが体験した表示速度だったり可用性です。 1990年代に、世界で最初にKeynote SystemsがSynthetic Monitoringを提供を開始した頃は、実際のユーザが体験した表示速度のデータを取る仕組みが無かったのです。
そこで、Keynote Systemsは、Webサイトやシステムに対して、定期的に1ユーザとしてアクセスして、パフォーマンスのデータを取得する、という手法だったのです。
2011年になって、Yahoo!のJavaScriptを使ってエンドユーザの体験している速度などを取得するBoomerangをリリースしたのがRUM(Real User Monitoring)の萌芽で、W3C Web Performance Working Groupでブラウザ上でユーザの体験速度を取得するAPIが整備されて、本格的に実ユーザの体験速度を取得できるようになりました。
それまでは、Synthetic Monitoringでしか、表示速度に関するデータを取得する方法が無かったのです。
「巨人の肩の上」に乗っている私達
現在の科学や技術は、先人の偉業の積み重ねの上に成り立っています。 それを「巨人の方の上に乗る」という表現をします。
もし、一部の人が、上述のような背景事情も知らずに、勝手に訳語を作ったならば、当然ながら、世界で使われている用語の意味と異なるわけですから、海外のエンジニアと日本のエンジニアの間で、Synthetic Monitoringの意味が異なってしまいます。それではいけないのです。
「外形監視」という訳語は、イメージしやすいですが、Synthetic Monitoringの本質を表していません。それではいけないのです。
エンジニアであるならば、きちんと先人の業績を尊重しましょう。 用語の由来などに気を付けましょう。
是非、「教育のためのTOC 日本支部」の「ツールの普及とコミュニティの健全な発展のための約束事」を読んでみて下さい。
http://tocforeducation.org/about/conventions-and-rules/tocforeducation.org
Synthetic Monitoringを「合成監視」という訳語を使うべき意味は、来年4月1日施行の改正民法債権法で必須となる品質保証にも関係があります。 2019年6月19日に開催した、html5jパフォーマンス部の勉強会で、Synthetic Monitoringの位置づけも解説したので、是非、動画をご覧下さい。
追記
コメントを色々拝見していますが、私が「巨人」という話ではないです。 世界で初めて、1997年にSynthetic Monitoringという分野を創りあげたKeynote Systemsが巨人だったのです。 Keynote Systemsは、2014年に、CEOのUmang Guputaが引退を決めて売却するまで、この分野ではマーケットシェアNo.1でした。
Synthetic Monitoringの訳語は、私が勝手に決めたわけではありません。 私自身も、Synthetic MonitoringのSyntheticという言葉に最初戸惑いました。 そして、Keynote Systemsが日本に進出する際に、経営陣や技術陣と協議して、その由来などを教えてもらってつけてます。
そのSynthetic Monitoringの由来も、記事中に書いてある通り、Synthetic Dataからきており、その訳語としては「合成データ」というのが存在しています。 「合成監視」という訳語にしたのは、それを尊重してのことです。
Keynote Systemsの社員達は、Keynotersと言われており、Keynote Systemsが売却された後、それぞれにCatchpointとかSplunkとか、新興の計測・監視サービスの立ち上げに関与して今も活躍しています。
追記2
「合成」ではなく「人工」の方が、訳語として適切ではないか?という意見をTwitterで拝見しました。
まず、日本語の意味として、人工と合成では、意味が以下のように異なります。
- 人工 … 自然の事物や現象に人間が手を加えること。
- 合成 … 二つ以上のものが結びついて一つになること。
もちろん、人工については、「人間の手で自然と同じようなものを作り出したり、自然と同じような現象を起こさせたりすること。」という意味もありますから、能動的にWebサイトにアクセスして、レスポンスを生成させるという行為が「人工」であるという解釈で「人工」という訳語もありうるでしょう。
しかし、Webサイトへのアクセスは、人が行うものであり、自然が行うものではないです。
計測という行為は、システムに対する一種の干渉行為で、システムに影響を与えます。 レスポンスは、概念的にはリクエストとシステムの力の合成と言えます。 光の反射のように遅延が生じなければ計測は必要なく、距離を速度で割ればいいだけの話です。
レスポンスは、リクエストの「力」がシステム処理の「力」によって影響を受けたもの、つまり力の合成です。
「システム負荷」とよく云いますが、リクエストは、システムに対して抑え込む「力」を持ち、リクエストが多いほどに、システム処理の力が抑え込まれます。 このように考えれば、力の合成という概念で、レスポンスタイムというデータが合成されているのだとご理解頂けるとかと思います。

追加 (2023年2月)
それでも、Synthetic Monitoringが、「合成監視」で納得できない、あなたに。
オライリーから発売された、「詳解システム・パフォーマンス 第2版」を是非購入してみて下さい。 とても良い本です。 本場のパフォーマンスエンジニアは、この本に書いてあるような統計学の知識と、モデルとメソドロジを使います。
この本の25ページをご覧になってください。 そこにこのような図が掲載されています。
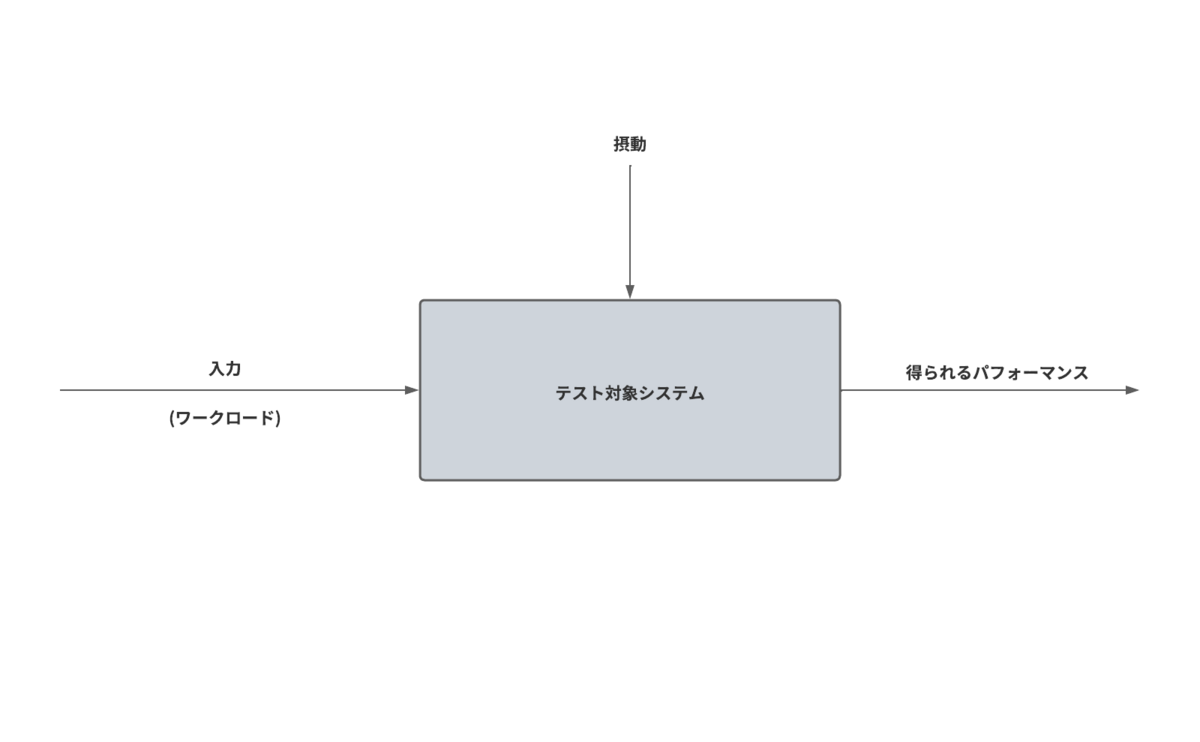
図の形は違いますが、言ってることは同じです。
この図で書いてある摂動とは、Wikipediaでは、以下のように記載されています。
摂動(せつどう、 英語: perturbation)とは、一般に力学系において、主要な力の寄与(主要項)による運動が、他の副次的な力の寄与(摂動項)によって乱される現象である。